
Problem Solving skill challenges face QA
QA "In my previous role, we were working on a project that involved migrating a legacy monolithic application to a microservices architecture. One of the major challenges we faced was ensuring seamless data migration without disrupting the existing business operations.
The legacy database schema was complex, and the data relationships were tightly coupled. As we transitioned to a microservices model, we needed to refactor the database schema to support independent services while maintaining data integrity. The challenge was to perform this migration without causing downtime or data inconsistencies.
To address this, I took the following approach:
Thorough Analysis: I conducted a detailed analysis of the existing database schema, identifying dependencies and potential points of failure during migration.
Incremental Refactoring: Instead of attempting a one-time migration, we opted for an incremental refactoring approach. We broke down the migration process into smaller, manageable tasks, focusing on one module at a time.
Data Versioning: We implemented data versioning mechanisms to ensure backward compatibility. This allowed us to support both the old and new data structures during the transition, preventing disruptions to ongoing operations.
Continuous Testing: Rigorous testing was crucial. We implemented a comprehensive suite of automated tests to validate data integrity and application functionality at each stage of the migration.
Rollback Plan: In case of unforeseen issues, we had a well-defined rollback plan. This included frequent backups, version-controlled database scripts, and a mechanism to revert to the previous state swiftly.
By following this approach, successfully migrated the application to a microservices architecture with minimal downtime and negligible impact on data integrity. The experience taught me the importance of careful planning, incremental changes, and continuous testing in tackling complex technical challenges."
Language Fundamentals:
Question: Can you explain the differences between value types and reference types in C#? Provide examples of each.
Value Types:
1. Stored on the Stack: Value types are stored directly in the memory location where the variable is declared, typically on the stack.
2. Contain Actual Data: The variable holds the actual data, and when you assign a value type to another variable or pass it as a parameter, a copy of the data is made.
3. Simple Types: Examples of value types include primitive data types such as integers, floating-point numbers, characters, and user-defined structs.
int x = 10; // 'x' is a value type
int y = x; // 'y' gets a copy of the value in 'x'
Console.WriteLine(x); // Output: 10
Console.WriteLine(y); // Output: 10
x = 20; // Changing 'x' does not affect 'y'
Console.WriteLine(x); // Output: 20
Console.WriteLine(y); // Output: 10
Reference Types:
1. Stored on the Heap: Reference types are stored on the heap, and variables store a reference (memory address) to the actual data.
2. Contain a Reference: When you assign a reference type to another variable or pass it as a parameter, you're copying the reference, not the actual data.
3. Complex Types: Examples of reference types include classes, arrays, interfaces, and user-defined class objects.
int[] arr1 = { 1, 2, 3 }; // 'arr1' is a reference type (array)
int[] arr2 = arr1; // 'arr2' now references the same array as 'arr1'
Console.WriteLine(arr1[0]); // Output: 1
Console.WriteLine(arr2[0]); // Output: 1
arr1[0] = 100; // Modifying the array through 'arr1' affects 'arr2'
Console.WriteLine(arr1[0]); // Output: 100
Console.WriteLine(arr2[0]); // Output: 100
Object-Oriented Programming (OOP): Question: Describe the principles of OOP and how they are applied in C#. Provide examples of polymorphism, encapsulation, and inheritance in your projects.
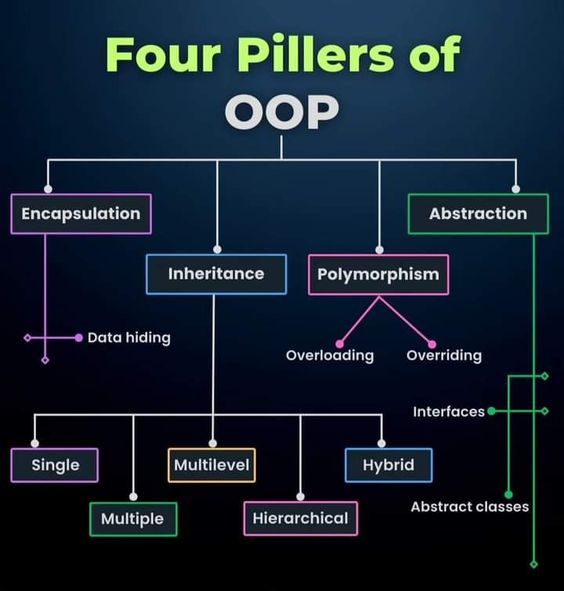
SOLID Principles in C#:
SOLID is a set of five design principles in object-oriented programming that aim to create more maintainable and scalable software. Here's a discussion of each principle and how they can be applied in C# based on your 14 years of experience:
*** Single Responsibility Principle (SRP):**
Each class should have only one reason to change. In C#, adhere to SRP by designing classes that have a single responsibility and delegate tasks to other classes when necessary. Example: Separate the responsibilities of data access and business logic into distinct classes.
*** Open/Closed Principle (OCP):**
Software entities (classes, modules, functions) should be open for extension but closed for modification. In C#, apply OCP by using abstraction and inheritance to allow for extension without modifying existing code. Example: Use interfaces and abstract classes to define contracts that can be implemented or extended without altering the existing code.
*** Liskov Substitution Principle (LSP):**
Subtypes should be substitutable for their base types without affecting the correctness of the program. In C#, follow LSP by ensuring that derived classes adhere to the behavior expected by their base classes. Example: Ensure that derived classes can be used interchangeably with their base classes without introducing unexpected behavior.
*** Interface Segregation Principle (ISP):**
Clients should not be forced to depend on interfaces they do not use. In C#, apply ISP by creating specific interfaces for specific clients, avoiding "fat" interfaces that force clients to implement unnecessary methods. Example: Create separate interfaces for different aspects of functionality, allowing clients to implement only the interfaces relevant to them.
*** Dependency Inversion Principle (DIP):**
High-level modules should not depend on low-level modules; both should depend on abstractions. Abstractions should not depend on details; details should depend on abstractions. In C#, implement DIP by relying on abstractions (interfaces, abstract classes) and injecting dependencies through constructor injection or dependency injection containers. Example: Instead of directly instantiating dependencies, inject them into a class through its constructor.
Application of SOLID Principles in Your Experience:
*** Architectural Design:**
Designing systems with a modular and extensible architecture, allowing for easy addition of new features without modifying existing code.
Code Maintainability:
Creating classes and modules with a single responsibility, making it easier to understand, maintain, and extend the codebase.
*** Testing:**
Facilitating unit testing by designing classes that are loosely coupled, making it simpler to isolate and test individual components.
*** Scalability:**
Enabling the scalability of systems by adhering to SOLID principles, allowing for the addition of new functionalities or the introduction of new components.
*** Collaborative Development:**
Promoting collaborative development by creating code that is easy to understand, reducing the chances of introducing bugs during collaboration. By incorporating SOLID principles into your C# development practices, you contribute to building robust, scalable, and maintainable software systems over your extensive 14-year experience.
Exception Handling: Question: How do you handle exceptions in C#? Can you explain the difference between catch and finally blocks?
Design Patterns: Question: Share your experience with design patterns in C#. Can you provide an example where you applied a design pattern to solve a specific problem?
We faced a scenario where multiple algorithms could be applied interchangeably to a specific task. To address this, I applied the Strategy design pattern.
Problem Statement:
We were developing an e-commerce platform where various discount strategies needed to be applied dynamically based on factors such as user type, order amount, or promotional events. Each discount strategy had a unique algorithm for calculating the discount.
Implementation:
// Define the strategy interface
public interface IDiscountStrategy
{
decimal ApplyDiscount(decimal orderTotal);
}
// Concrete strategy implementations
public class RegularCustomerDiscountStrategy : IDiscountStrategy
{
public decimal ApplyDiscount(decimal orderTotal)
{
// Logic for calculating discount for regular customers
// ...
}
}
public class VIPCustomerDiscountStrategy : IDiscountStrategy
{
public decimal ApplyDiscount(decimal orderTotal)
{
// Logic for calculating discount for VIP customers
// ...
}
}
public class HolidayDiscountStrategy : IDiscountStrategy
{
public decimal ApplyDiscount(decimal orderTotal)
{
// Logic for calculating holiday-specific discount
// ...
}
}
// Context class that utilizes the selected strategy
public class OrderProcessor
{
private readonly IDiscountStrategy _discountStrategy;
public OrderProcessor(IDiscountStrategy discountStrategy)
{
_discountStrategy = discountStrategy;
}
public decimal ProcessOrder(decimal orderTotal)
{
// Additional order processing logic
// ...
// Apply the selected discount strategy
return _discountStrategy.ApplyDiscount(orderTotal);
}
}
Usage:
// Client code selects and uses a specific discount strategy
var regularCustomerStrategy = new RegularCustomerDiscountStrategy();
var orderProcessor = new OrderProcessor(regularCustomerStrategy);
decimal discountedTotal = orderProcessor.ProcessOrder(originalOrderTotal);
Key Points:
Flexibility: The Strategy pattern allowed us to define a family of algorithms, encapsulate each algorithm, and make them interchangeable. This flexibility was crucial as new discount strategies could be added without modifying existing code.
Separation of Concerns: Each discount strategy encapsulated its unique logic, promoting a separation of concerns and maintainability.
Dynamic Selection: The Context class (OrderProcessor) could dynamically switch between different discount strategies at runtime, accommodating various scenarios.
Asynchronous Programming: Question: Explain the concept of asynchronous programming in C#. How does the async and await keywords work, and when would you use them?
Asynchronous programming in C# is a programming paradigm that allows the execution of non-blocking operations, enabling the application to perform other tasks while waiting for certain operations to complete. The primary mechanism for asynchronous programming in C# is through the use of the async and await keywords.
How async and await Work: async Modifier:
The async modifier is used to define an asynchronous method. An asynchronous method contains one or more await expressions.
async Task<int> MyAsyncMethod()
{
// Asynchronous operations
return await SomeAsyncOperation();
}
await Keyword:
The await keyword is used to indicate that a particular operation is asynchronous. It tells the compiler to pause execution until the awaited operation completes.
async Task<int> MyAsyncMethod()
{
int result = await SomeAsyncOperation();
// Code here executes after SomeAsyncOperation completes
return result;
}
The await keyword can be applied to any method that returns a Task or Task
When to Use async and await: I/O-bound Operations:
Use async and await for I/O-bound operations such as file I/O, database queries, or network requests. Asynchronous programming allows the application to remain responsive while waiting for these operations to complete.
UI Applications:
In UI applications, use async and await to prevent blocking the main thread. This ensures a smooth and responsive user interface.
private async void Button_Click(object sender, EventArgs e)
{
resultLabel.Text = await FetchDataAsync();
}
Concurrency:
Asynchronous programming is beneficial for concurrent execution of multiple tasks without blocking threads. It is particularly useful in scenarios where parallelism can improve performance. Parallel Operations:
When dealing with parallel operations, asynchronous programming allows you to efficiently manage multiple tasks concurrently.
async Task<string[]> ProcessDataAsync()
{
Task<string> task1 = GetDataAsync();
Task<string> task2 = ProcessDataAsync();
// Concurrently await both tasks
string result1 = await task1;
string result2 = await task2;
return new string[] { result1, result2 };
}
Long-Running Operations:
Use async and await for long-running operations to prevent blocking the calling thread. This is crucial for applications that require responsiveness.
async Task<int> FetchDataAsync()
{
// Simulating an asynchronous operation
await Task.Delay(2000); // Represents I/O-bound operation
return 42;
}
async Task Main()
{
Console.WriteLine("Start");
// Asynchronous method call
int result = await FetchDataAsync();
Console.WriteLine($"Result: {result}");
Console.WriteLine("End");
}
In this example, the FetchDataAsync method simulates an asynchronous operation, and the await keyword is used to asynchronously wait for its completion without blocking the main thread. The application remains responsive during the asynchronous delay.
Memory Management: Question: Discuss the garbage collection mechanism in C#. How do you optimize memory usage in large-scale applications?
** Garbage Collection in C#:**
Garbage collection in C# is an automatic memory management process where the runtime environment (Common Language Runtime - CLR) is responsible for reclaiming memory occupied by objects that are no longer in use. The key points regarding garbage collection in C# include:
Automatic Memory Management: C# employs a garbage collector that runs in the background and identifies objects that are no longer reachable. The garbage collector frees up memory occupied by these unreachable objects, preventing memory leaks.
Generational Garbage Collection: C# uses a generational garbage collection model, categorizing objects into three generations (young, middle-aged, and old). Newly created objects are placed in the young generation, and those surviving garbage collection move to the next generation.
Garbage Collection Process:
The garbage collector performs collection in several phases, including marking, compacting, and releasing memory.
During the marking phase, the collector identifies reachable objects.
The compacting phase rearranges memory to reduce fragmentation.
Finally, memory is released in the releasing phase.
GC.SuppressFinalize and IDisposable: Objects can implement the IDisposable interface to provide a mechanism for releasing unmanaged resources explicitly. The GC.SuppressFinalize method can be used to suppress the finalization of an object if explicit cleanup has already been performed. Optimizing Memory Usage in Large-Scale Applications:
Object Pooling: Use object pooling to reuse and recycle objects, reducing the frequency of object creation and garbage collection.
Dispose Unmanaged Resources: Implement the IDisposable interface to ensure proper disposal of unmanaged resources like file handles, database connections, etc.
Large Object Heap (LOH) Considerations: Be mindful of large objects that are allocated on the Large Object Heap (LOH). Excessive use of the LOH can impact garbage collection efficiency.
Minimize Finalization: Avoid unnecessary finalization by releasing resources explicitly when possible. Finalization can delay object reclamation.
Generational Approach: Leverage the generational garbage collection model by designing applications that produce short-lived objects. Most objects are collected in the younger generations, reducing the impact on performance.
Memory Profiling Tools: Use memory profiling tools to identify memory leaks and optimize memory usage. Tools like ANTS Memory Profiler, dotMemory, or Visual Studio Memory Usage Analyzer can be valuable.
Tune Garbage Collection Parameters: Adjust garbage collection settings, such as GC latency modes, to align with application requirements. Balancing latency and throughput is crucial.
Regular Code Reviews: Regularly review code to ensure proper resource disposal and efficient memory usage practices are followed.
LINQ (Language-Integrated Query): Question: How do you use LINQ in C#? Provide an example of a scenario where LINQ improves code readability and efficiency.
** Utilizing LINQ in C#:**
LINQ (Language Integrated Query) is a powerful feature in C# that allows seamless querying of various data sources. Its application significantly enhances code readability and efficiency, especially when dealing with collections and complex data manipulations.
Example Scenario: Filtering and Projecting Data from a List
Problem Statement:
We have a list of Person objects, and we need to retrieve the names of all adults (age greater than or equal to 18) from the list.
Without LINQ:
List<Person> people = GetPeople(); // Assume a method that populates the list
List<string> adultNames = new List<string>();
foreach (Person person in people)
{
if (person.Age >= 18)
{
adultNames.Add(person.Name);
}
}
Using LINQ:
List<Person> people = GetPeople();
List<string> adultNames = people
.Where(person => person.Age >= 18)
.Select(person => person.Name)
.ToList();
Benefits of Using LINQ:
Readability: The LINQ query is more concise and declarative, making it easier to understand at a glance. The intent of the code (filtering adults and extracting names) is expressed directly.
Efficiency: LINQ operations are optimized and provide a level of abstraction that allows the underlying runtime to optimize the execution. Additionally, LINQ queries are lazily evaluated, meaning that the data is processed only when needed.
Expressiveness: LINQ allows chaining multiple operations together, such as filtering (Where) and projecting (Select), leading to expressive and compact code.
Type Safety: LINQ queries benefit from compile-time type checking, reducing the chances of runtime errors.
Conclusion:
In this scenario, LINQ greatly improves the readability and efficiency of the code by providing a more expressive and concise way to query and manipulate data. The LINQ syntax aligns with the natural language of querying, making the code both more readable and maintainable.
Dependency Injection: Question: Explain the benefits of dependency injection in C#. How do you implement dependency injection in your projects?
Multithreading: Question: Discuss multithreading in C#. How do you handle synchronization and prevent race conditions in a multithreaded environment?
** Multithreading in C#:**
Multithreading in C# allows the execution of multiple threads concurrently, enhancing performance and responsiveness in applications. However, it introduces challenges such as race conditions and requires careful synchronization to ensure thread safety.
Handling Synchronization and Preventing Race Conditions:
Locking Mechanisms:
Use the lock keyword or Monitor class to enforce mutual exclusion. This ensures that only one thread at a time can execute a specific block of code.
private static readonly object lockObject = new object();
// ...
lock (lockObject)
{
// Critical section
}
- Mutex and Semaphore:
Utilize synchronization primitives like Mutex and Semaphore for more advanced synchronization scenarios.
using (Mutex mutex = new Mutex())
{
// ...
mutex.WaitOne();
// Critical section
mutex.ReleaseMutex();
}
- ReaderWriterLockSlim:
For scenarios where multiple threads can read but only one can write, use ReaderWriterLockSlim to improve concurrency.
private static readonly ReaderWriterLockSlim rwLock = new ReaderWriterLockSlim();
// ...
rwLock.EnterReadLock();
// Read operation
rwLock.ExitReadLock();
Interlocked Operations:
- Employ Interlocked class methods for atomic operations to avoid race conditions when updating shared variables.
Interlocked.Increment(ref counter);
- Monitor.Pulse and Monitor.Wait: Use Monitor.Pulse and Monitor.Wait for signaling between threads when certain conditions are met.
lock (lockObject)
{
// ...
Monitor.Wait(lockObject);
}
- Thread-Safe Collections:
Prefer thread-safe collections (e.g., ConcurrentQueue, ConcurrentDictionary) to avoid explicit locking when working with shared data structures.
Immutable Data:
Design classes with immutability in mind to reduce the need for synchronization. Immutable objects are inherently thread-safe. Task Parallel Library (TPL):
Leverage TPL for simplified multithreading. TPL includes constructs like Parallel.For and Parallel.ForEach that handle parallelism without explicit thread management. ThreadLocal
: Use ThreadLocal
to create variables that are unique to each thread, eliminating the need for synchronization in some scenarios. Volatile Keyword: When working with variables shared between threads, use the volatile keyword to ensure that reads and writes are not cached.
ASP.NET Core:
**Question: Share your experience with ASP.NET Core. How do you implement middleware, and what are the key differences between ASP.NET and ASP.NET Core? ** I have extensively worked with ASP.NET Core, a modern, open-source, cross-platform framework for building cloud-based, internet-connected applications. My involvement includes designing and implementing solutions using ASP.NET Core, ensuring scalability, security, and maintainability.
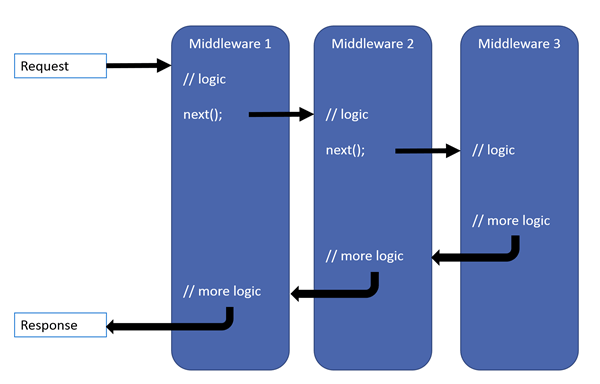
Middleware Implementation:
Middleware in ASP.NET Core is a pipeline of components that can handle requests and responses. It plays a crucial role in processing HTTP requests and shaping responses. Here's a brief overview of how middleware is implemented in ASP.NET Core:
Configuration
- Settings files, such as appsettings.json
- Environment variables
- Azure Key Vault
- Azure App Configuration
- Command-line arguments
- Custom providers, installed or created
- Directory files
- In-memory .NET objects
Configuration in Startup.cs: Middleware components are configured in the Startup.cs file within the Configure method. They are added to the application pipeline using extension methods like UseMiddlewareName.
public void Configure(IApplicationBuilder app)
{
app.UseMiddleware
Custom Middleware: Custom middleware is often created to perform specific tasks in the request-response pipeline. Middleware components implement the IMiddleware interface or use the InvokeAsync method.
public class CustomMiddleware : IMiddleware
{
public async Task InvokeAsync(HttpContext context, Func<Task> next)
{
// Middleware logic before the next middleware
await next.Invoke(); // Call the next middleware in the pipeline
// Middleware logic after the next middleware
}
}
Built-in Middleware: ASP.NET Core includes a set of built-in middleware for common tasks such as routing, authentication, logging, etc. For example, UseMvc adds the MVC middleware for handling requests. Key Differences Between ASP.NET and ASP.NET Core:
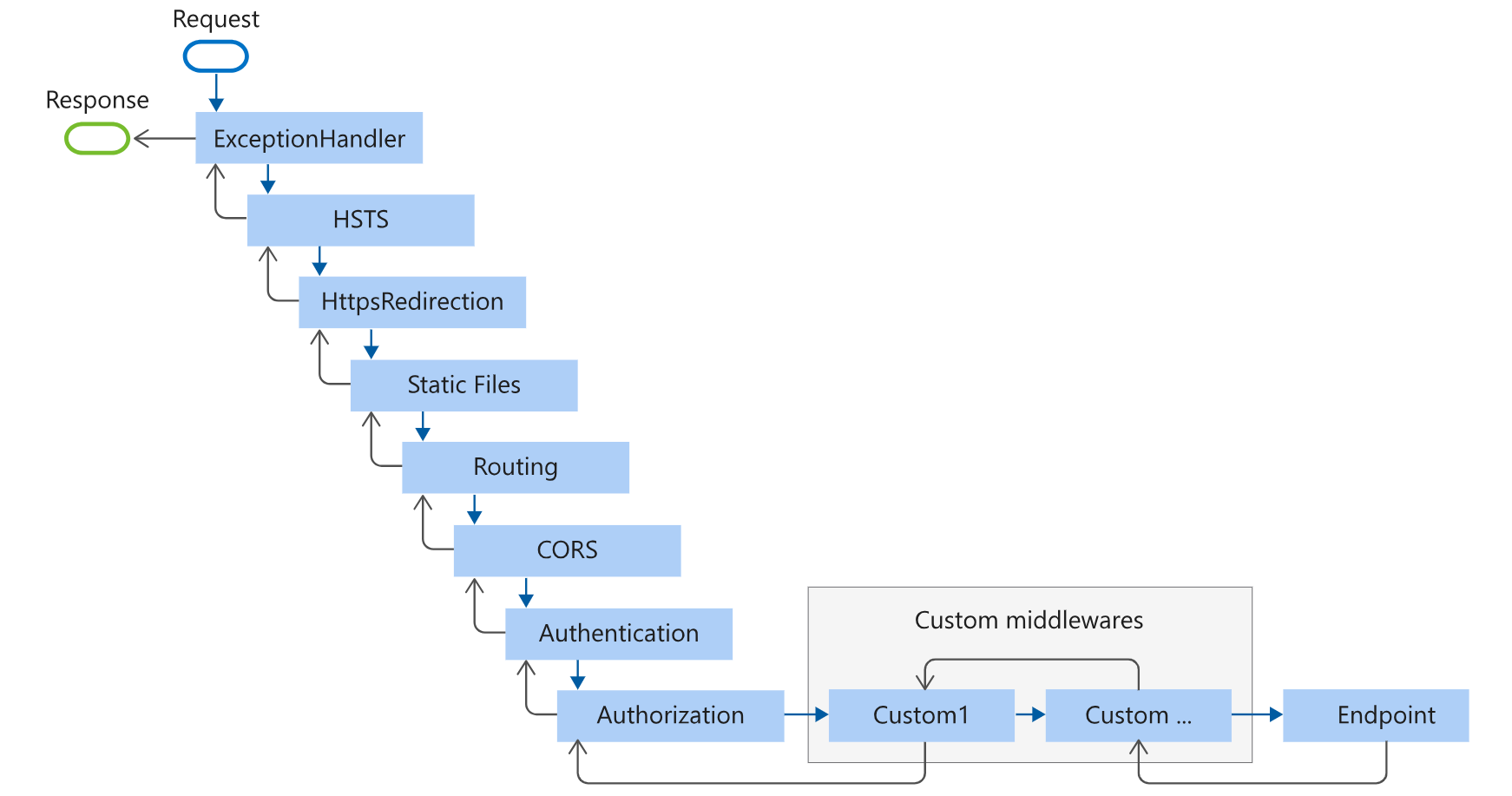
Cross-Platform: ASP.NET Core is designed to be cross-platform, supporting Windows, Linux, and macOS, whereas traditional ASP.NET primarily targets Windows.
Modularity and Middleware: ASP.NET Core emphasizes modularity and middleware. The middleware pipeline allows more control over the request-response flow.
Dependency Injection: ASP.NET Core has built-in support for dependency injection, making it a first-class citizen. In traditional ASP.NET, dependency injection was added later.
Unified Framework: ASP.NET Core is a unified framework that merges ASP.NET MVC, Web API, and Web Pages into a single framework. Traditional ASP.NET had separate frameworks for MVC and Web API.
Performance: ASP.NET Core is known for its improved performance compared to traditional ASP.NET. It is lightweight and optimized for high-throughput applications.
.NET Core and .NET Framework: ASP.NET Core is built on top of .NET Core, a modular and cross-platform framework. Traditional ASP.NET is built on the .NET Framework, primarily targeting Windows.
Open Source: ASP.NET Core is open-source, encouraging community contributions and rapid updates. Traditional ASP.NET is not open-source. Hosting Models:
ASP.NET Core supports a variety of hosting models, including self-hosting and hosting within IIS. Traditional ASP.NET relies heavily on IIS for hosting.
Unit Testing: **Question: How do you approach unit testing in C#? Provide an example of a scenario where unit testing uncovered a critical issue.
Code Optimization: Question: What strategies do you use for optimizing C# code for performance? Can you share an example where optimization led to significant improvements?
Optimizing C# code for performance involves various strategies to enhance speed, reduce resource consumption, and improve overall efficiency. Here are some common strategies, along with an example:
Algorithmic Optimization: Example: Consider optimizing an algorithm with a higher time complexity. For instance, replacing a nested loop with a more efficient algorithm or using a data structure with faster lookup times can lead to significant performance improvements.
Memory Management: Example: Minimize unnecessary object creation and use object pooling where applicable. Reducing the number of allocations and garbage collection cycles can enhance memory efficiency. For instance, in a scenario with frequent data processing, reuse objects instead of creating new ones.
Concurrency and Parallelism: Example: Utilize parallel programming constructs (e.g., Parallel.ForEach in C#) to distribute workloads across multiple cores. This can be beneficial in scenarios involving data processing or computations, where parallelization can lead to faster execution.
Database Query Optimization: Example: Optimize database queries by indexing columns, retrieving only necessary data, and using appropriate join strategies. This can significantly improve the performance of data-intensive applications. For instance, consider optimizing a slow SQL query by adding indexes or restructuring the query for better efficiency.
Caching: Example: Implement caching mechanisms to store frequently accessed data in memory. This reduces the need to recalculate or fetch data from slower sources. For example, caching results of expensive calculations or frequently accessed database queries can improve response times.
Lazy Loading: Example: Use lazy loading for resources that are not immediately required. For instance, defer loading non-essential components until they are actually needed. This can be applied to scenarios like loading images or initializing resources on-demand.
Batch Processing: Example: Instead of processing items one by one, consider batch processing. This reduces the overhead of individual operations. For example, when dealing with a large number of records, batch insert/update operations can outperform individual transactions.
Compiler Optimizations: Example: Leverage compiler optimizations by using appropriate compiler flags and settings. For instance, enabling compiler optimizations (/optimize flag in C#) can result in more efficient code generation and better runtime performance.
Profiler and Performance Monitoring: Example: Use profilers and performance monitoring tools to identify bottlenecks and areas for improvement. For instance, profiling code execution can reveal specific functions or methods that consume the most resources, guiding targeted optimizations.
Hardware-Specific Optimization: Example: Tailor optimizations based on the target hardware. For instance, taking advantage of hardware-specific instructions or optimizations for certain architectures can yield better performance.
Architectural Considerations:
Question: How do you design the architecture of a scalable and maintainable C# application? Discuss the key components and their interactions. Answer:-
Layered Architecture:
Presentation Layer (Web/API): This layer handles user interactions and serves as the entry point. It includes controllers, views, and API endpoints.
Business Logic Layer: This layer contains the core application logic, handling business rules, validations, and workflows.
Data Access Layer: Responsible for interacting with the database or external data sources. It includes repositories, data models, and database connections.
Separation of Concerns:
- Models: Define data structures and business entities.
- Services: Contain business logic and domain-specific operations.
- Repositories: Handle data access and database interactions.
Dependency Injection:
IoC Container: Use a dependency injection container to manage the application's dependencies and facilitate loose coupling between components.
Scalability:
- Load Balancing: Distribute incoming requests across multiple servers to ensure optimal resource utilization.
- Caching: Implement caching mechanisms to reduce the load on the database and enhance performance.
- Microservices (Optional): Consider breaking down the application into microservices for independent scalability.
** Asynchronous Processing:**
- Message Queues: Use message queues (e.g., RabbitMQ, Azure Service Bus) for handling background jobs and decoupling components.
- Async/Await: Employ asynchronous programming to improve responsiveness and scalability.
** Security:**
- Authentication and Authorization:** Implement secure authentication mechanisms (e.g., OAuth) and define roles and permissions.
- Data Encryption: Encrypt sensitive data in transit and at rest.
Logging and Monitoring:
Logging Framework: Use a robust logging framework (e.g., Serilog) to capture relevant information for debugging and auditing. Monitoring Tools: Implement monitoring tools (e.g., Application Insights, ELK stack) to track application performance and identify issues.
** Testing:**
Unit Testing: Write comprehensive unit tests for individual components.
Integration Testing: Verify the interactions between different layers and components.
Automated Testing: Implement automated testing as part of the CI/CD pipeline.
Continuous Integration/Continuous Deployment (CI/CD):
CI/CD Pipeline: Set up a pipeline for automated builds, testing, and deployment.
Deployment Strategies: Implement strategies like blue-green deployment or canary releases for minimizing downtime during updates.
Documentation:
Code Documentation: Document code to facilitate understanding and maintenance.
Architecture Documentation: Provide high-level documentation outlining the application's architecture, key components, and interactions.
Continuous Integration and Deployment (CI/CD):
Question: Explain your experience with CI/CD in C# development. How do you ensure a smooth deployment pipeline?
CI/CD is a software development practice that enables developers to automatically build, test, and deploy their code changes. Here are some key steps and considerations for setting up a smooth CI/CD pipeline in C# development:
1. Version Control:
Use a version control system like Git to track changes in your codebase. Branching strategies such as Gitflow can help manage feature development, bug fixes, and releases.
2. Automated Builds: Utilize a build automation tool like MSBuild or third-party tools like Jenkins, TeamCity, or Azure DevOps for automated builds. Ensure that the build process is defined in a script file (e.g., a .csproj file) and can be executed consistently.
3. Automated Testing: Implement unit tests, integration tests, and other relevant tests to ensure code quality. Use testing frameworks like MSTest, NUnit, or xUnit. Integrate testing into your CI pipeline to automatically run tests on each code commit.
4. Code Quality Analysis: Incorporate code analysis tools such as SonarQube or Roslyn Analyzers to ensure code quality and adherence to coding standards. Analyze code metrics and static code analysis as part of your CI process.
5. Artifact Management: Utilize a package manager like NuGet to manage dependencies. Host your own NuGet repository or use a service like Azure Artifacts to manage and share packages.
6. Continuous Deployment: Automate deployment scripts using tools like Octopus Deploy, Azure DevOps, or Jenkins. Implement environment-specific configuration management to handle different deployment scenarios (development, staging, production).
7. Monitoring and Logging: Integrate application performance monitoring and logging tools to identify issues in production. Utilize logging frameworks like Serilog or log4net.
8. Security Scanning: Integrate security scanning tools to identify vulnerabilities in your code. Regularly update dependencies and libraries to patch security vulnerabilities.
9. Infrastructure as Code (IaC): Use Infrastructure as Code tools like Terraform or Azure Resource Manager templates to define and manage your infrastructure. Include infrastructure changes as part of your CI/CD pipeline.
10. Documentation: Document your CI/CD pipeline, including configuration settings, deployment steps, and any troubleshooting information. By following these practices and continuously refining your CI/CD pipeline, you can ensure a smoother development and deployment process, reducing the likelihood of errors and improving overall software quality. Regularly review and update your pipeline to incorporate new tools and best practices in the evolving landscape of CI/CD.
** Key Characteristics of Microservices Architecture:**
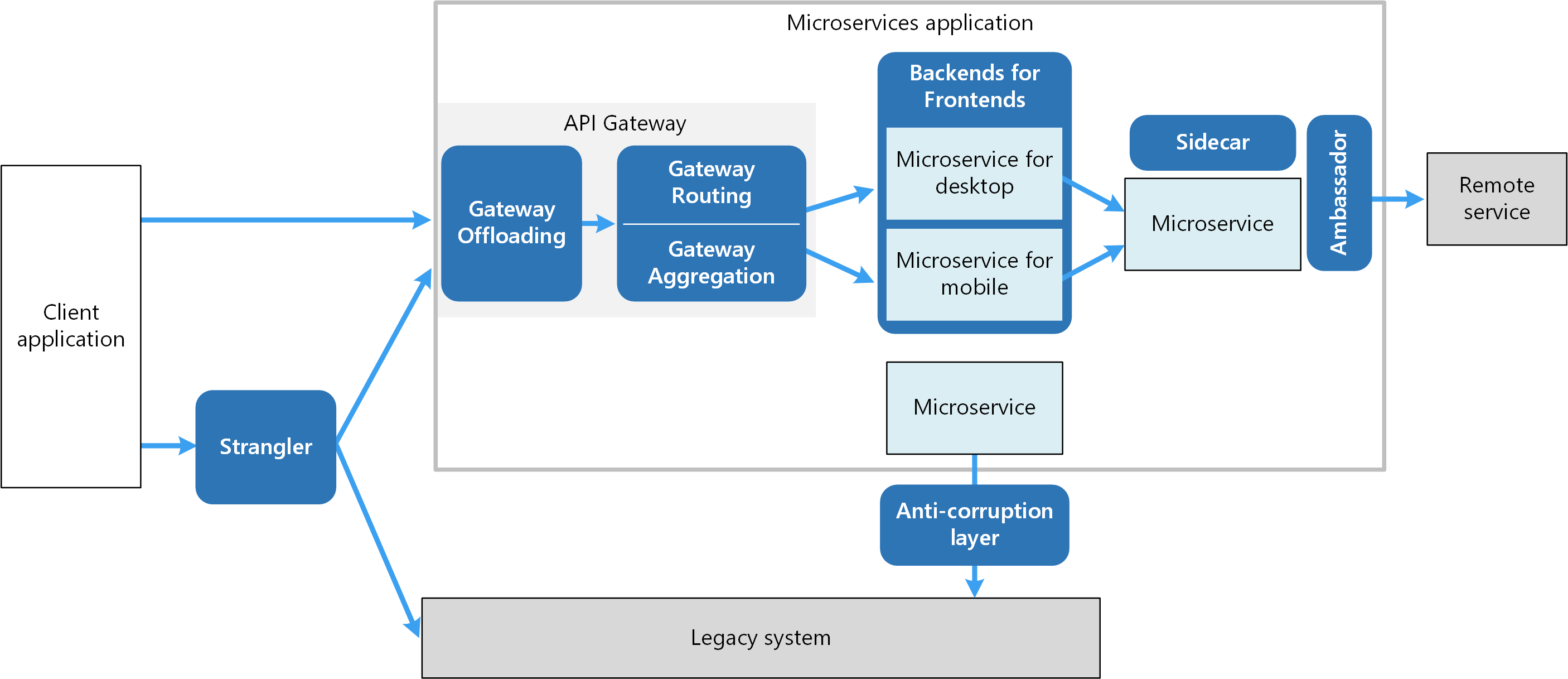
Cloud Desgin Patter
https://learn.microsoft.com/en-us/azure/architecture/patterns/
Modularity:
Microservices are organized as small, independent services, each focused on a specific business capability. Each microservice can be developed, deployed, and scaled independently, facilitating modular development and maintenance. Independence:
Microservices are autonomous, meaning they can be developed, deployed, and scaled independently of other services. Teams can work on different microservices concurrently, promoting faster development cycles and agility. Decentralized Data Management:
Each microservice typically has its own database, and data is decentralized across services. Data consistency is maintained through mechanisms such as eventual consistency, transactions, or event-driven communication. Resilience:
Failure in one microservice does not necessarily impact the entire system. Microservices are designed to be resilient in the face of failures. Fault isolation is achieved through techniques like circuit breakers, retries, and graceful degradation. Scalability:
Microservices can be independently scaled based on demand for specific services. This allows for efficient resource utilization and better performance. Scaling is not tied to the entire application but can be focused on specific functionalities. Technology Diversity:
Different microservices can be implemented using different technologies, frameworks, and programming languages, depending on the specific requirements of the service. Teams have the flexibility to choose the best tools for the job. API-Based Communication:
Microservices communicate with each other through well-defined APIs. This communication can be synchronous (RESTful APIs) or asynchronous (messaging queues). This standardized communication enables interoperability and flexibility in service interactions. Continuous Delivery and Deployment:
Microservices architecture aligns well with continuous integration and continuous delivery (CI/CD) practices. Services can be deployed independently, allowing for faster releases and updates without affecting the entire application.
Q How do you handle communication between microservices? Discuss the pros and cons of various communication patterns (e.g., REST, gRPC, message queues).
Communication between microservices is a critical aspect of microservices architecture. Choosing the right communication pattern depends on the specific requirements and characteristics of your system. Here are some common communication patterns, along with their pros and cons:
1. REST (Representational State Transfer): Pros:
Simplicity: RESTful APIs are easy to understand and implement, making them a popular choice for web-based communication. Statelessness: RESTful services are stateless, which simplifies scalability and reliability. Interoperability: Can be used over HTTP, making it platform-agnostic and accessible from various programming languages and frameworks. Caching: Takes advantage of HTTP caching mechanisms for improved performance. Cons:
Overhead: REST relies on text-based protocols like JSON, which can result in higher overhead compared to binary protocols. Limited Request/Response Styles: Typically follows a request-response style, which might not be suitable for scenarios requiring streaming or real-time communication. 2. gRPC (Remote Procedure Call): Pros:
Efficiency: gRPC uses a binary protocol (Protocol Buffers) that is more efficient in terms of payload size and serialization/deserialization. Bi-directional Streaming: Supports bidirectional streaming, enabling efficient communication for scenarios like real-time updates. Code Generation: Can generate client and server code in multiple programming languages, improving consistency and reducing development effort. Cons:
Complexity: gRPC can be more complex to implement and debug compared to REST, especially for developers unfamiliar with Protocol Buffers. HTTP/2 Dependency: gRPC relies on HTTP/2, which may not be supported in certain environments or by some existing infrastructure. 3. Message Queues (e.g., RabbitMQ, Apache Kafka): Pros:
Asynchronous Communication: Enables decoupling of services through asynchronous message passing, improving overall system resilience. Scalability: Facilitates horizontal scalability by allowing services to process messages independently. Event-Driven Architecture: Supports event-driven patterns, making it suitable for scenarios where events trigger actions in other services. Cons:
Complexity: Introduces additional complexity in terms of message broker setup, maintenance, and error handling. Eventual Consistency: Asynchronous communication can lead to eventual consistency challenges, requiring careful consideration of data synchronization.
Considerations for Choosing Communication Patterns: 1. Latency Requirements:
Consider the latency requirements of your system. Real-time communication patterns like gRPC or WebSocket might be suitable for low-latency scenarios. 2. Data Size and Payload:
Evaluate the size of data being transmitted. RESTful APIs might be appropriate for smaller payloads, while gRPC or binary protocols may be more efficient for larger payloads. 3. Service Independence:
Consider whether services need to be loosely or tightly coupled. Message queues and asynchronous communication patterns offer loose coupling, while RESTful APIs might provide tighter integration. 4. Development Team Skill Set:
Assess the skill set of your development team. If they are more comfortable with REST or have experience with a specific technology, it may influence the choice of communication pattern. 5. Scalability Requirements:
Consider the scalability requirements of your system. Asynchronous patterns and message queues are often chosen for their ability to scale horizontally. 6. Tooling and Infrastructure:
Evaluate the existing infrastructure and tooling. Some communication patterns may require specific infrastructure support, and it's essential to ensure compatibility.
Explain the importance of service discovery in a microservices ecosystem. What tools or strategies have you used for service discovery in .NET Core?
Service discovery is a critical aspect of microservices architecture, especially in dynamic and distributed environments. In a microservices ecosystem, where services are deployed independently and can dynamically scale, service discovery plays a key role in managing and facilitating communication between services. Here's an explanation of the importance of service discovery and some tools and strategies used in .NET Core:
Importance of Service Discovery: *** Dynamic Scaling:**
Microservices can be dynamically scaled up or down based on demand. Service discovery allows new instances to register themselves and be discovered by other services or clients. *** Load Balancing:**
Service discovery enables load balancers to distribute incoming requests across multiple instances of a service. This ensures optimal resource utilization and improved performance. *** Fault Tolerance:**
In a dynamic environment, services may fail or become unavailable. Service discovery helps detect service changes and updates the routing accordingly, improving fault tolerance and resilience. *** Decentralized Communication:**
Microservices communicate with each other through well-defined APIs. Service discovery facilitates the decentralized nature of communication by providing a mechanism for locating services dynamically. *** Improved Developer Productivity:**
Developers can focus on writing code without worrying about the exact location or IP addresses of other services. Service discovery abstracts these details, simplifying development and deployment processes.
Service Discovery Strategies: *** Client-Side Service Discovery:**
Clients (services or applications) are responsible for discovering and connecting to other services. Popular in scenarios where clients have built-in load balancing and retry mechanisms. Tools: Netflix Eureka, Consul, etcd.
- Server-Side Service Discovery:
A dedicated service registry or discovery server maintains a centralized list of all available services. Clients query the registry to discover the location of other services. Tools: Consul, etcd, Kubernetes Service Discovery. *** Container Orchestration Service Discovery:**
Container orchestration platforms like Kubernetes provide built-in service discovery mechanisms. Services are assigned a DNS name or IP address that is automatically managed by the orchestration platform. Tools: Kubernetes DNS service discovery. Service Discovery in .NET Core: *** Eureka with Spring Cloud:**
Netflix Eureka is a popular service discovery and registry tool. While it is part of the Spring Cloud ecosystem, .NET Core applications can use the Eureka server for service discovery.
Integration libraries like Steeltoe provide support for Eureka in .NET Core. Consul:
HashiCorp Consul is a service discovery and service mesh tool. It can be used with .NET Core applications to register and discover services. The Consul .NET SDK allows developers to interact with the Consul API. *** Kubernetes Service Discovery:**
In a Kubernetes environment, services can use Kubernetes DNS service discovery. Each service is assigned a DNS name based on its service name. .NET Core applications running in Kubernetes can leverage this DNS-based service discovery. *** Steeltoe:**
Steeltoe is an open-source project that provides a set of libraries for .NET Core developers building microservices. It includes components for service discovery, circuit breakers, and distributed tracing. Steeltoe integrates with service discovery tools like Eureka and Consul. Example of Service Discovery in .NET Core using Eureka: Add Steeltoe.Eureka.Client NuGet Package:
dotnet add package Steeltoe.Discovery.Client.Eureka
Configure Eureka in Startup.cs:
services.AddDiscoveryClient(Configuration);
Configure Eureka Client in appsettings.json:
{ "eureka": { "client": { "shouldRegisterWithEureka": true, "serviceUrl": "http://eureka-server:8761/eureka/" } } } Run and Register with Eureka:
When the .NET Core service starts, it registers itself with the Eureka server. Service discovery is crucial for maintaining the dynamic and decentralized nature of microservices communication. Whether using third-party tools or native solutions, implementing service discovery ensures that microservices can effectively discover, connect, and communicate with each other in a scalable and resilient manner.
The Microsoft.Extensions.ServiceDiscovery package includes the following endpoint selector providers:
*PickFirstServiceEndPointSelectorProvider.Instance: Pick-first, which always selects the first endpoint.
*RoundRobinServiceEndPointSelectorProvider.Instance: Round-robin, which cycles through endpoints.
*RandomServiceEndPointSelectorProvider.Instance: Random, which selects endpoints randomly.
*PowerOfTwoChoicesServiceEndPointSelectorProvider.Instance: Power-of-two-choices, which attempt to pick the least used endpoint based on the Power of Two Choices algorithm for distributed load balancing, degrading to randomly selecting an endpoint when either of the provided endpoints don't have the IEndPointLoadFeature feature.