
Azure SQL DB High Availability & Disaster Recovery

Azure SQL Database provides industry leading high availability guarantee of at least 99.99% to support mission critical and a wide variety of applications that need to be always available. Azure SQL Database also has capability to have turn key business continuity solution that lets you perform quick disaster recovery in the event of a regional outage. This article contains valuable information to review in advance of application deployment.

High availability checklist
The following are recommended configurations that you can implement to maximize availability:
- Enable zone redundancy where available for the database or elastic pool to ensure resiliency from a larger set of failures in a region.
- Incorporate retry logic in the application to handle transient errors.
- Use maintenance windows to make impactful maintenance events predictable and less disruptive.
- Test application fault resiliency by manually triggering a failover to see built in High Availability in action.

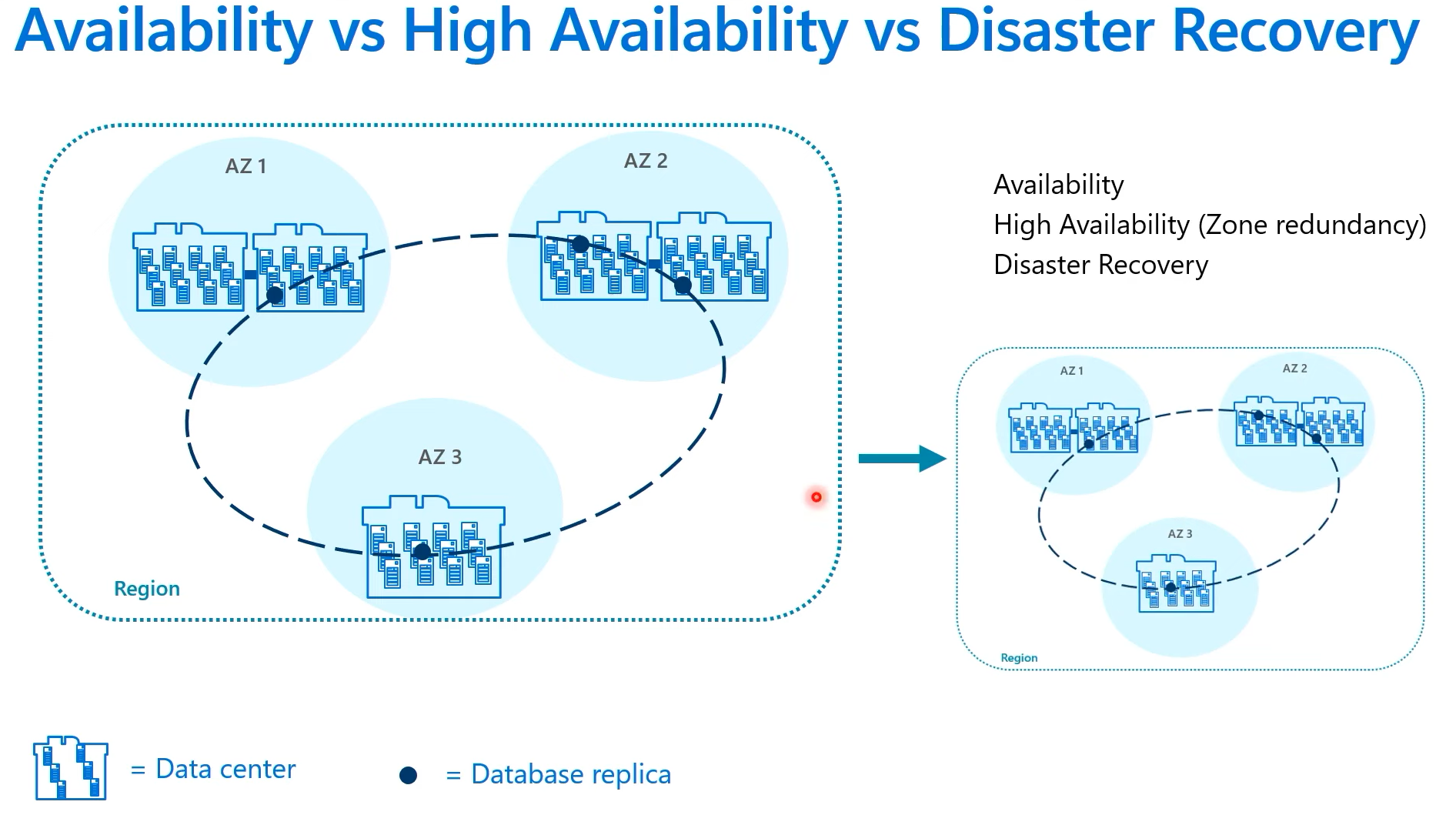
Disaster recovery checklist
To be best prepared for disaster recovery, follow these recommendations:
- Enable active geo-replication to have a readable secondary database in a different Azure region.
- Enable auto-failover groups for a group of databases. Use the read-write and read-only listener endpoints that remain unchanged after failover. With auto-failover groups, you can set the failover mode to automatic (default) or manual.
- Ensure that the geo-secondary database is created with the same service tier, compute tier (provisioned or serverless) and compute size (DTUs or vCores) as the primary database.
- When scaling up, scale up the geo-secondary first, and then scale up the primary.
- When scaling down, reverse the order: scale down the primary first, and then scale down the secondary.
- Disaster recovery by nature is designed to make use of asynchronous replication of data between primary and secondary region. To prioritize data availability over higher commit latency, consider calling the sp_wait_for_database_copy_sync stored procedure immediately after committing the transaction. Calling sp_wait_for_database_copy_sync blocks the calling thread until the last committed transaction has been transmitted and hardened in the transaction log of the secondary database.
- Monitor lag with respect to Recovery Point Objective (RPO), using the replication_lag_sec column of the sys.dm_geo_replication_link_status dynamic management view (DMV) on the primary database. It shows lag in seconds between the transactions committed on the primary and hardened to the transaction log on the secondary. For example, assume that the lag is one second at a point in time. If the primary is impacted by an outage and a geo-failover is initiated at that point in time, transactions committed in the last second will be lost.
- Configure the backup storage redundancy option to Geo-redundant backup storage to use geo-restore capability. This option isn't available in regions with no region pair.
- Frequently plan and execute disaster recovery drills so that you're better prepared in the event of a real outage.
Configure your database after recovery
Important It is recommended to conduct periodic drills of your disaster recovery strategy to verify application tolerance, as well as all operational aspects of the recovery procedure. The other layers of your application infrastructure may require reconfiguration. For more information on resilient architecture steps, review the Azure SQL Database high availability and disaster recovery checklist.
Reference :- https://learn.microsoft.com/en-us/azure/azure-sql/database/disaster-recovery-guidance?view=azuresql https://learn.microsoft.com/en-us/azure/azure-sql/database/high-availability-disaster-recovery-checklist?view=azuresql